Publications
Peer-Reviewed Articles
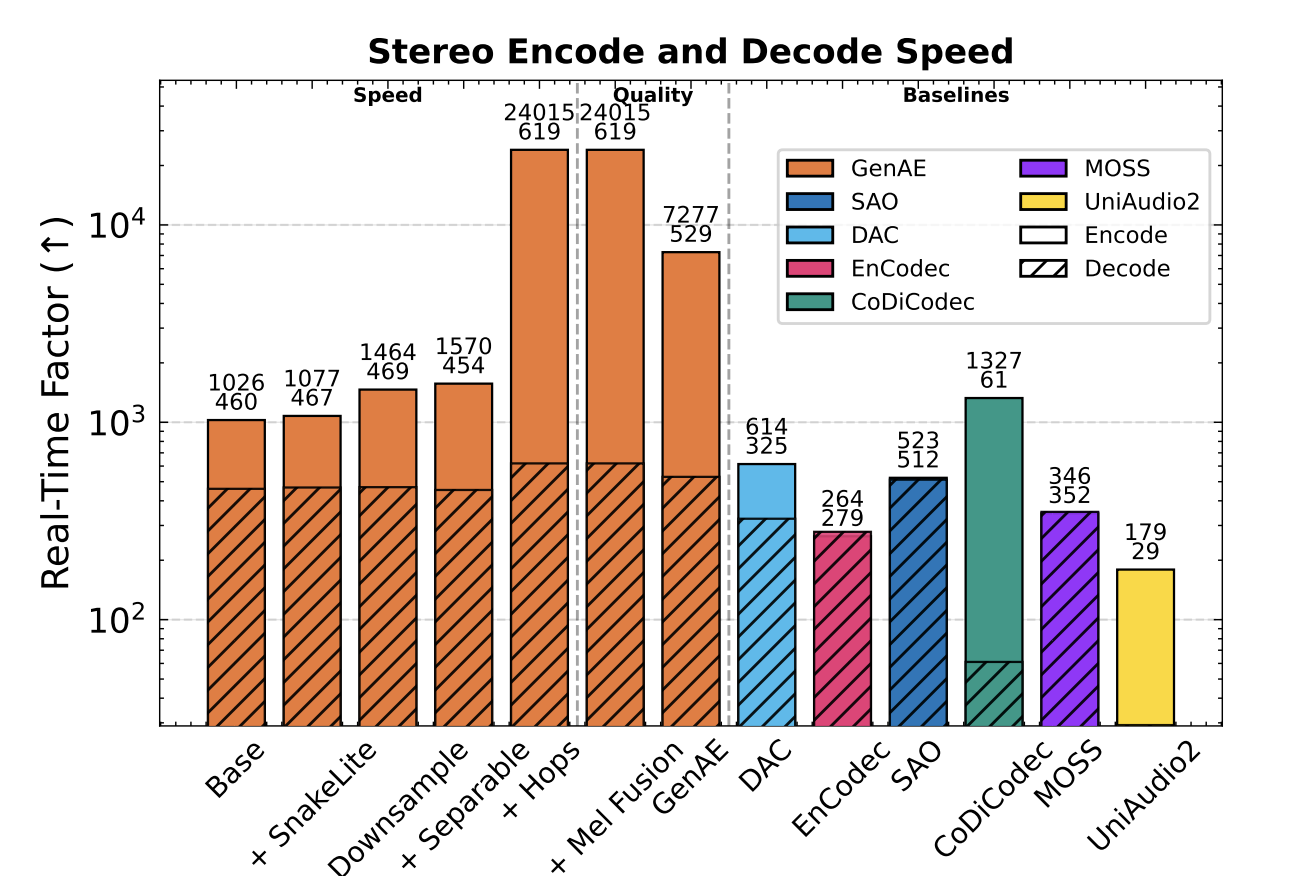
A Generative-First Neural Audio Autoencoder
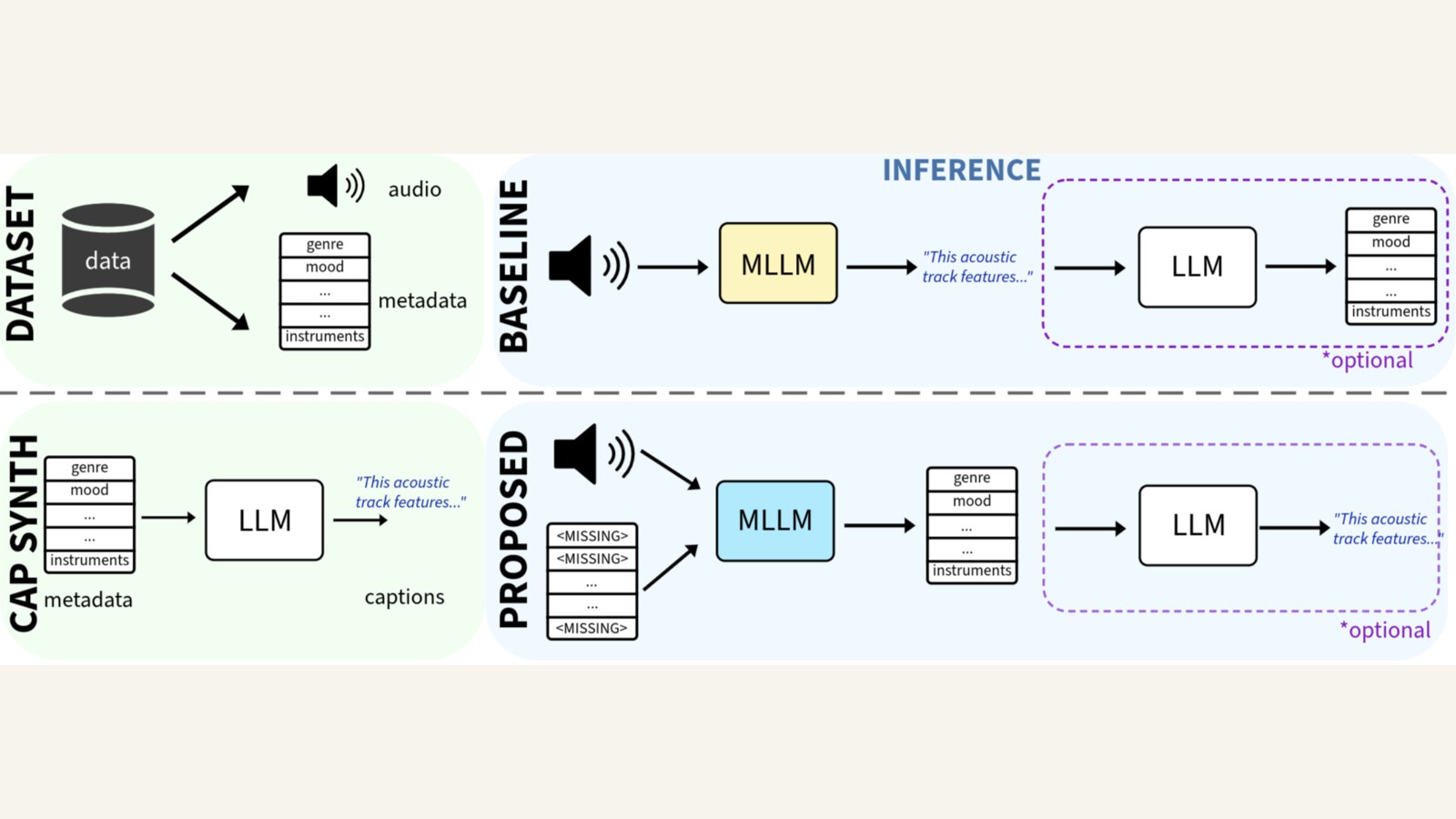
Rethinking Music Captioning with Music Metadata LLMs

On Class Separability Pitfalls In Audio-Text Contrastive Zero-Shot Learning
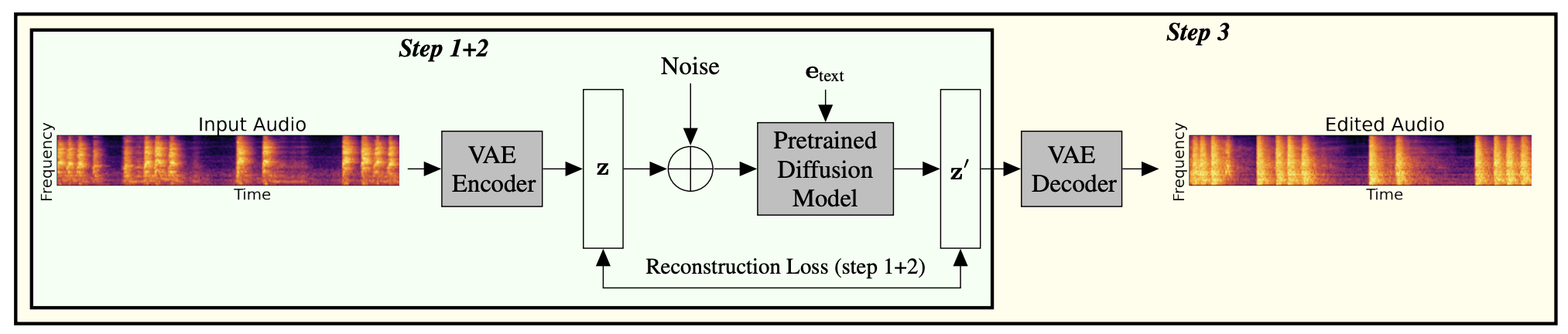
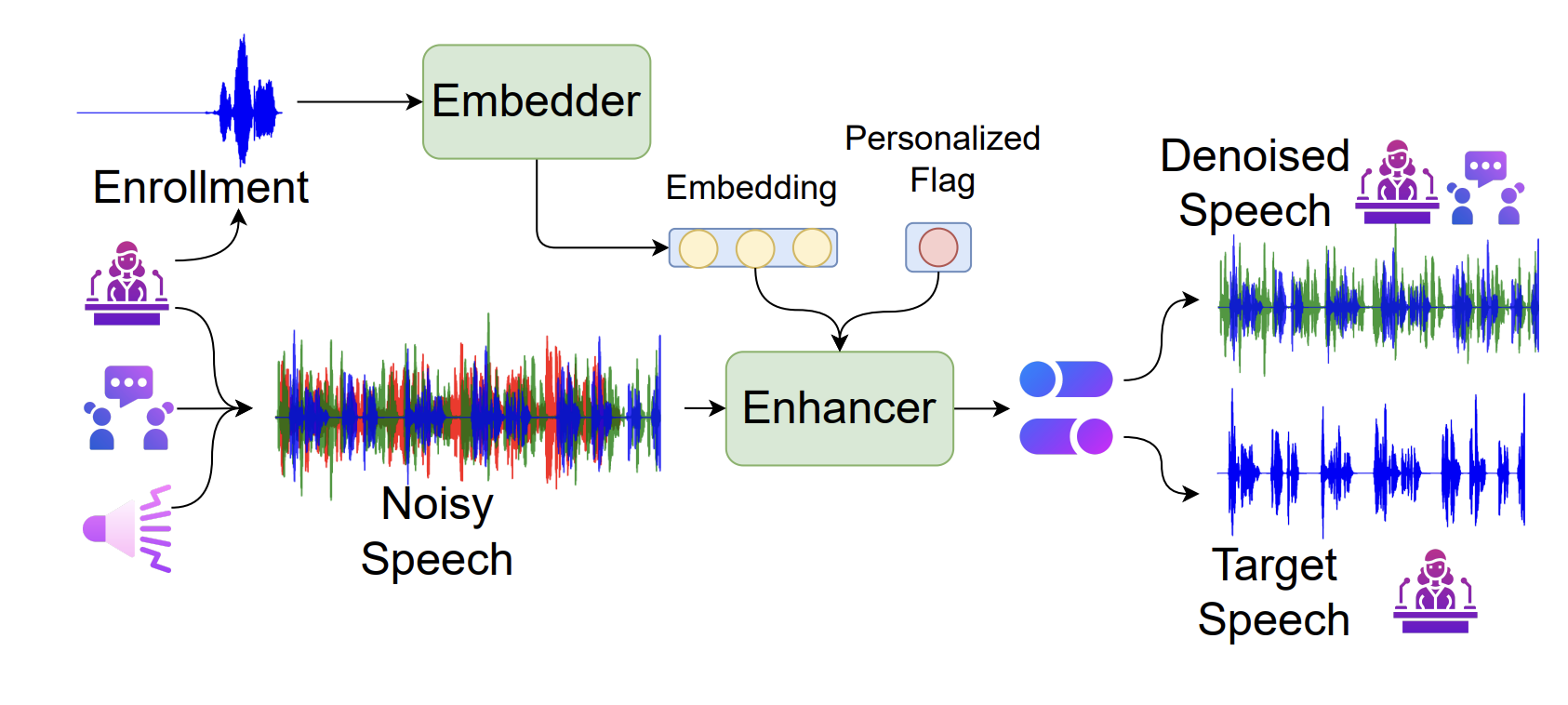
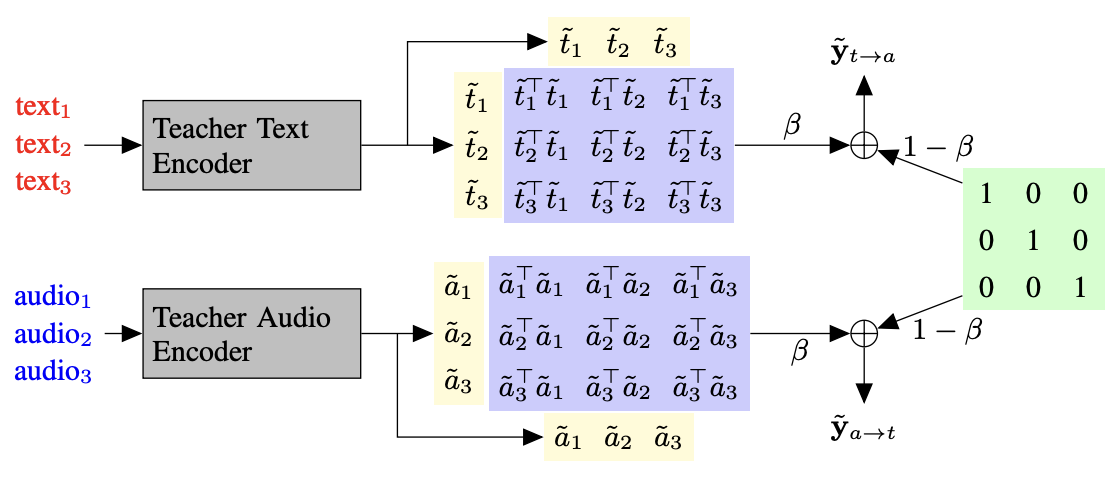

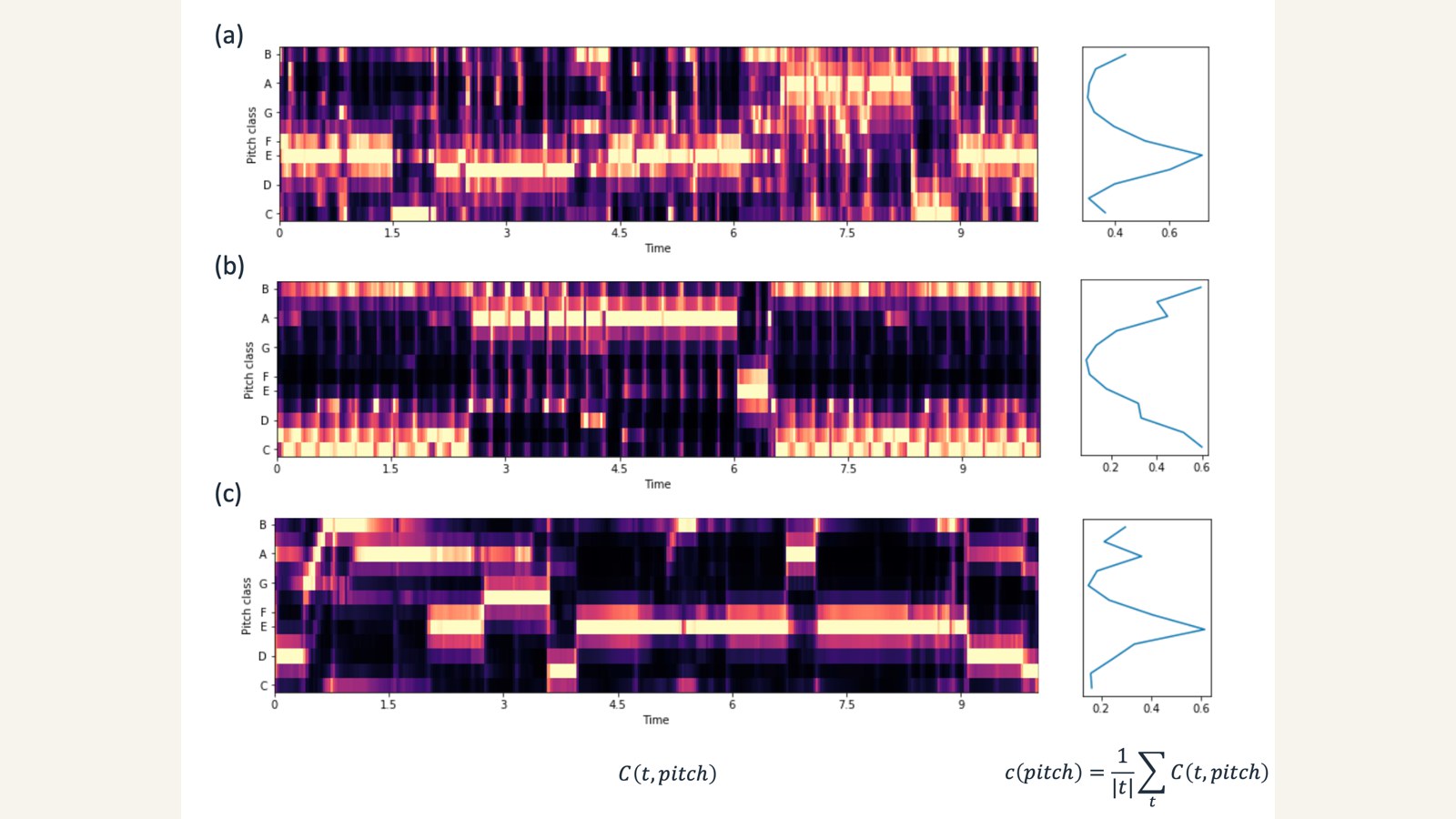
Improved Singing Voice Separation with Chromagram-Based Pitch-Aware Remixing
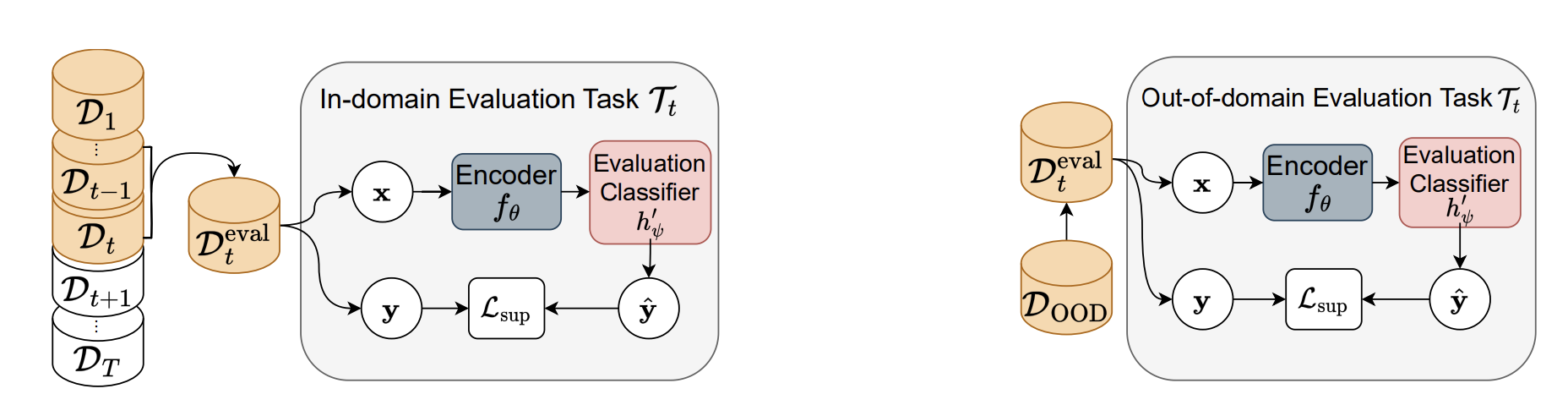
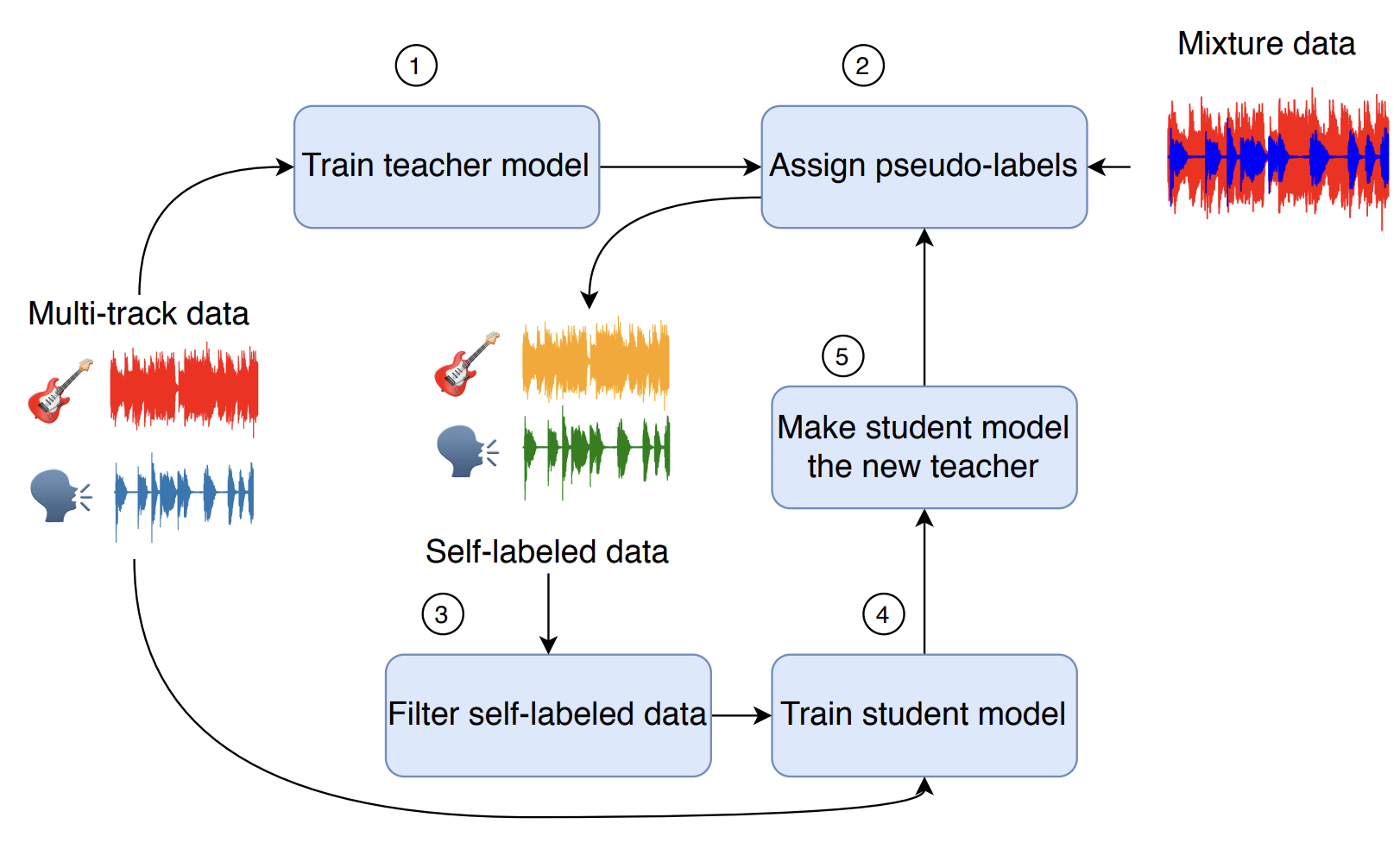

Separate But Together: Unsupervised Federated Learning for Speech Enhancement from Non-IID Data
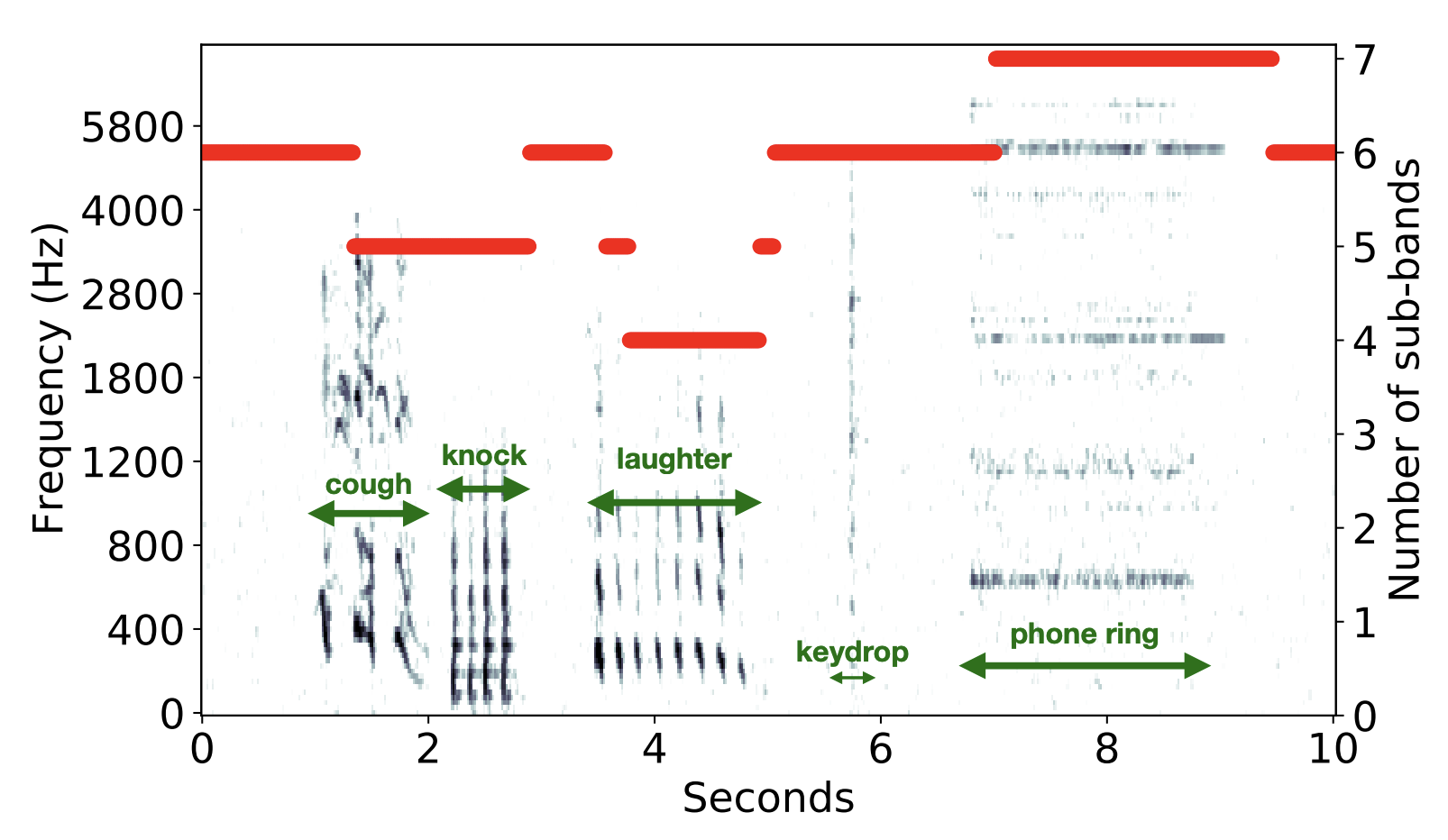
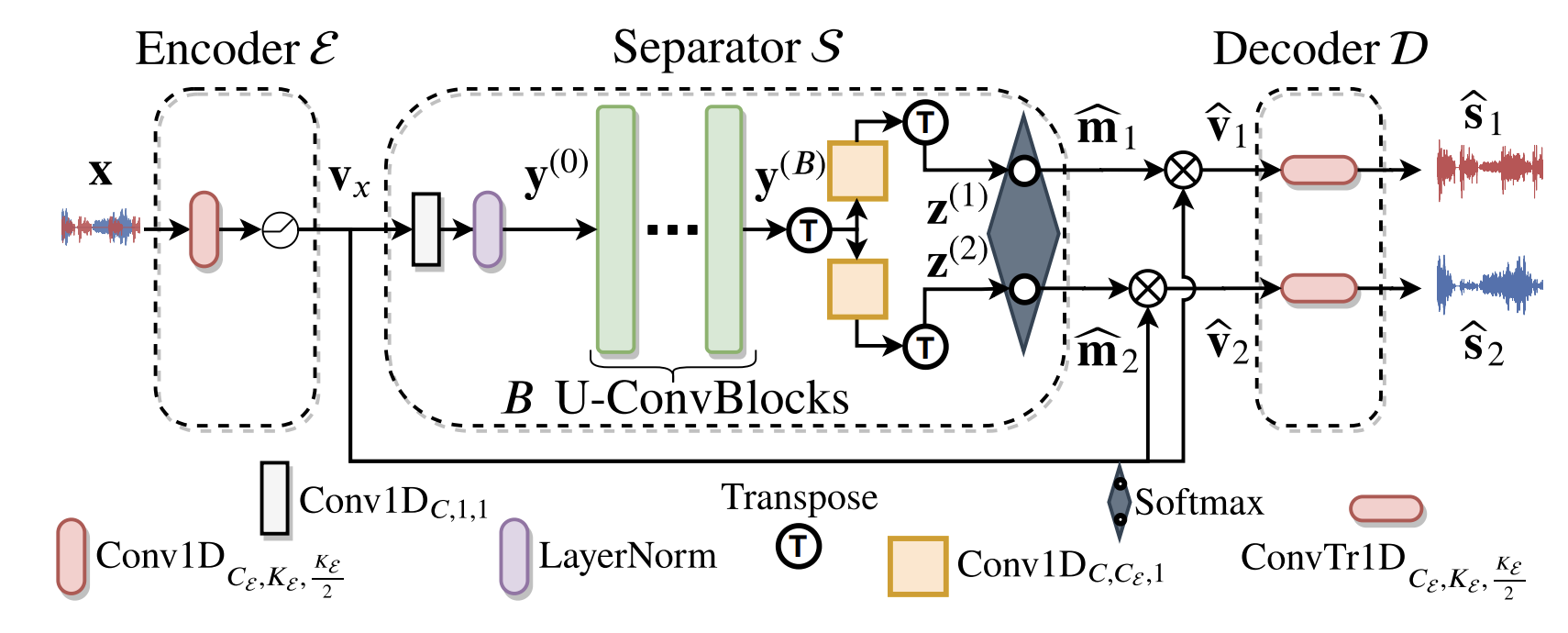

Two-Step Sound Source Separation: Training On Learned Latent Targets
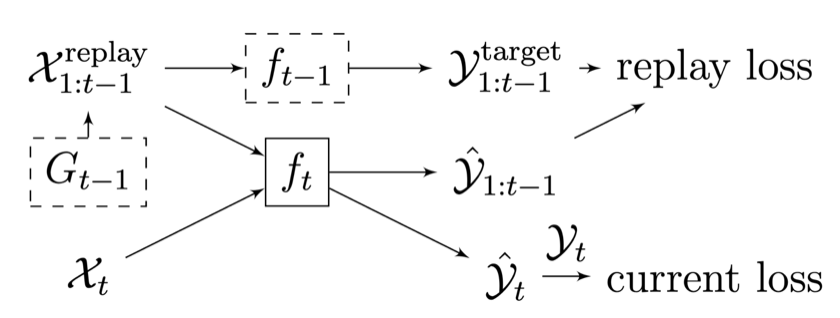
Continual Learning of New Sound Classes Using Generative Replay
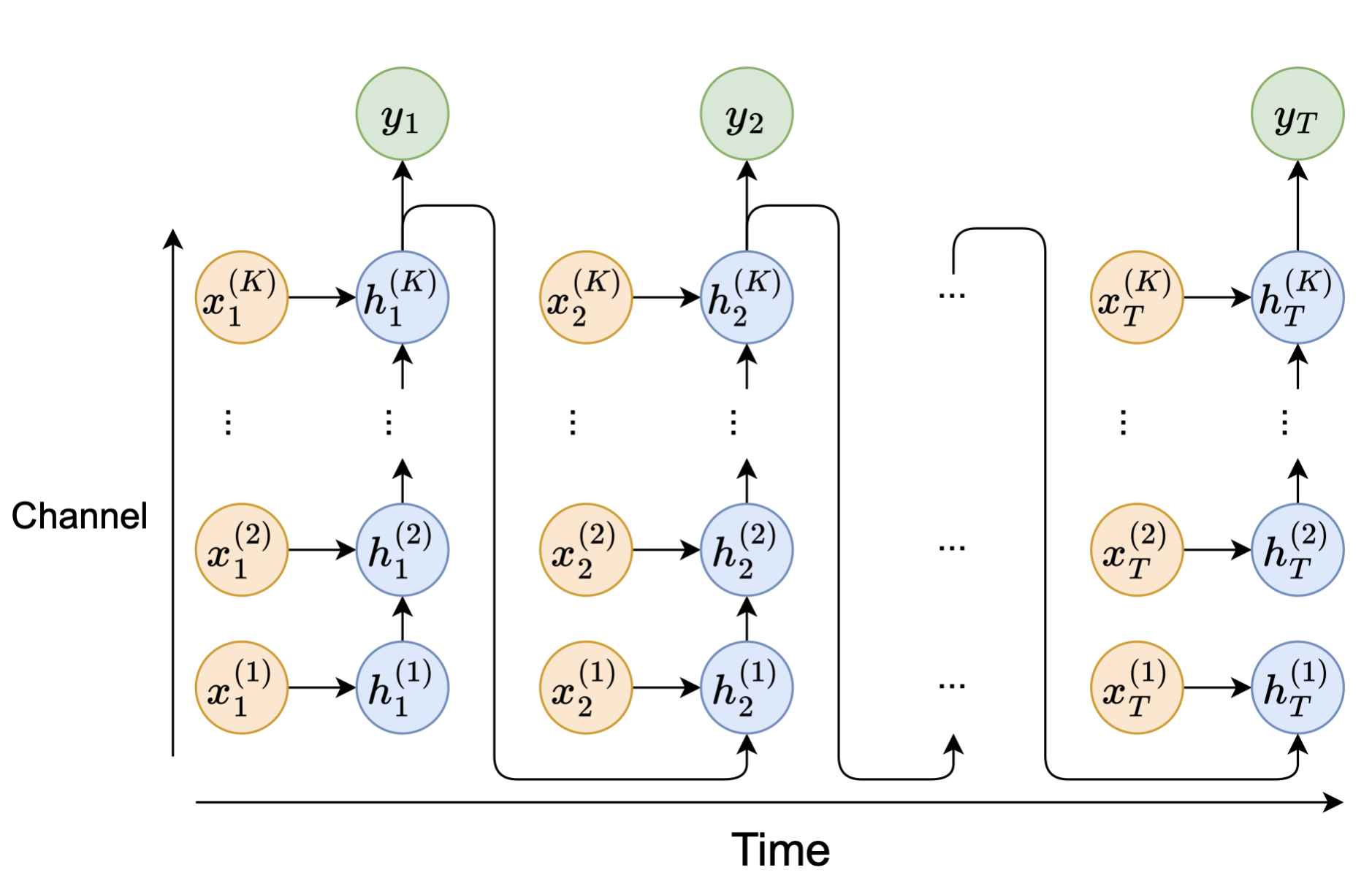
Multi-View Networks For Multi-Channel Audio Classification
Preprints

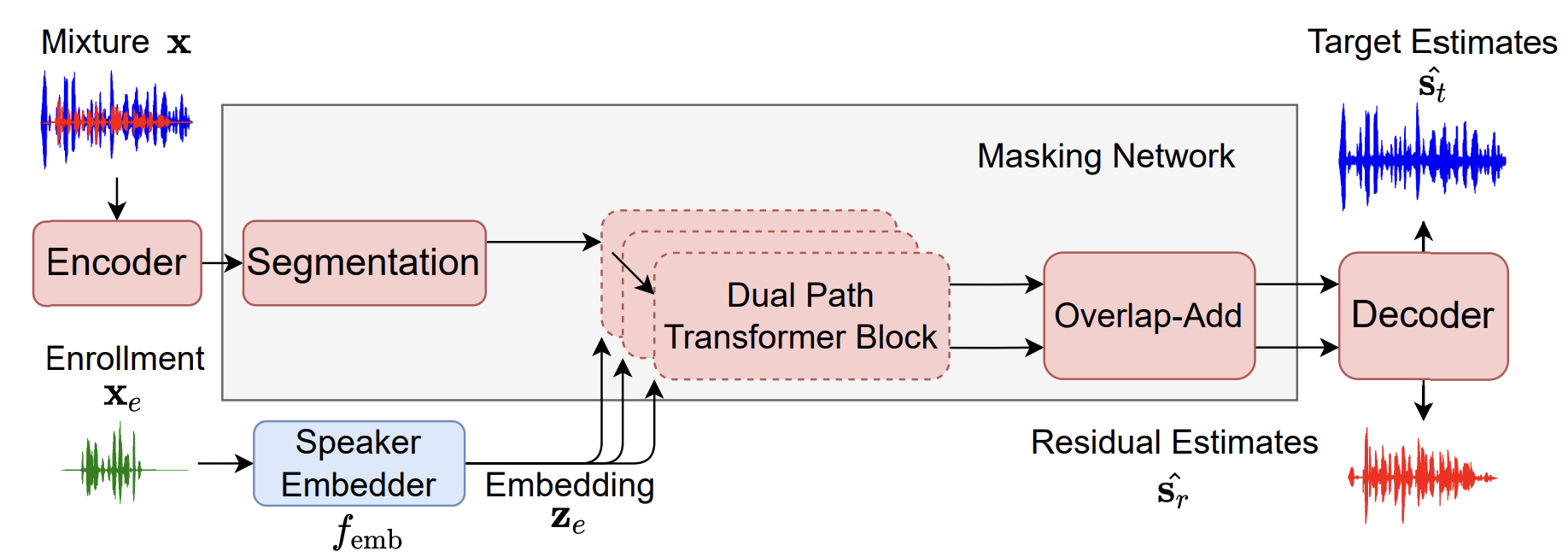
Patents and Patent Applications
Reports
Thesis
Citation