
Hello! I am a researcher at the MusicAI Group of Adobe Research. My work focuses on machine learning for music, audio, and speech, including music and audio understanding, text-to-music generation, sound recognition, source separation, speech enhancement, and multimodal representation learning.
Before joining Adobe, I was an applied scientist at Amazon Web Services (AWS) and also interned there several times, working on real-time speech enhancement, personalized audio processing, and enterprise search. I earned my Ph.D. in Computer Science from the University of Illinois Urbana-Champaign in 2023, advised by Prof. Paris Smaragdis. Prior to my Ph.D., I received my B.S. in Computer Science from Harvey Mudd College in 2018.
Selected Work
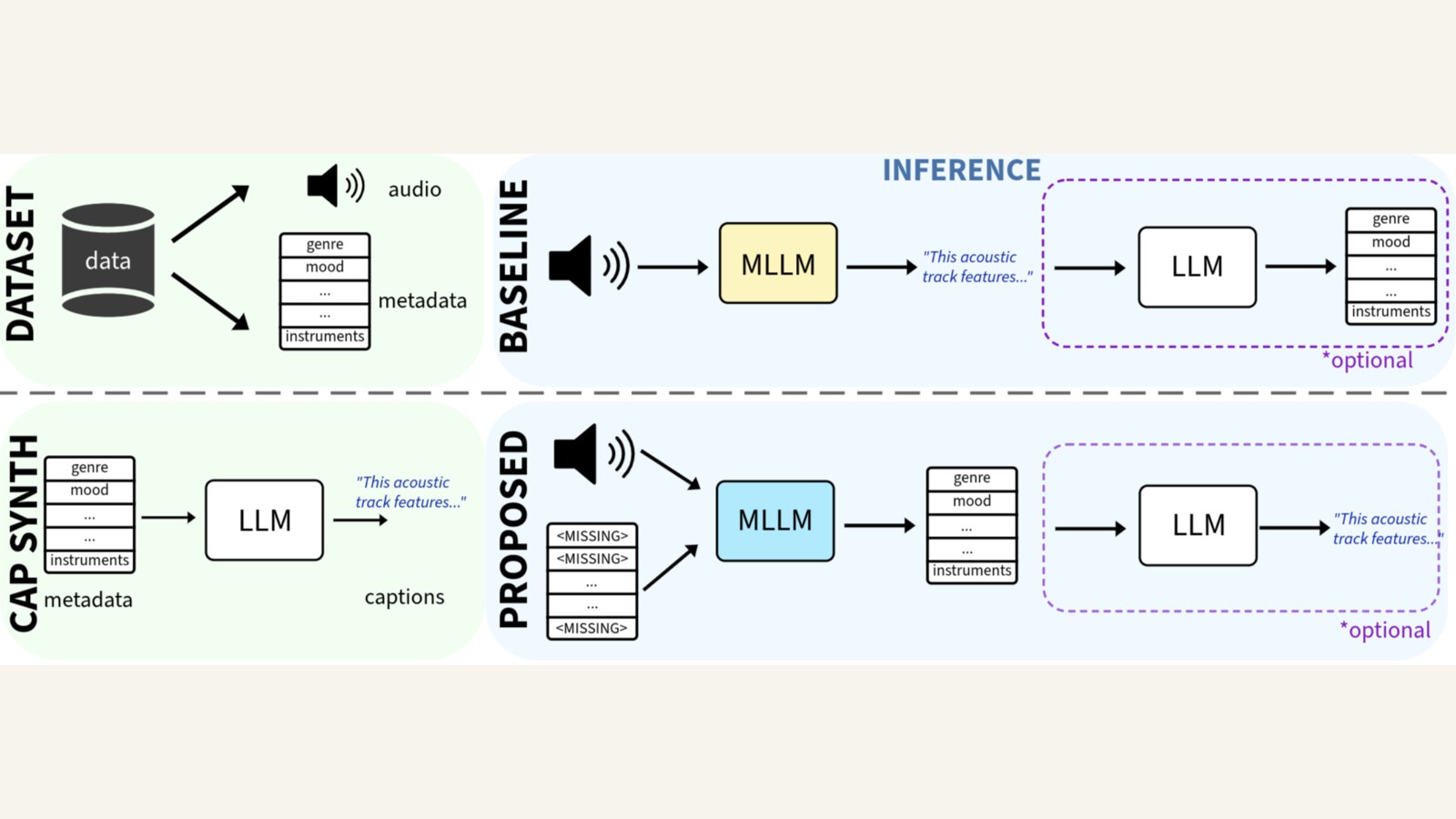
Rethinking Music Captioning with Music Metadata LLMs
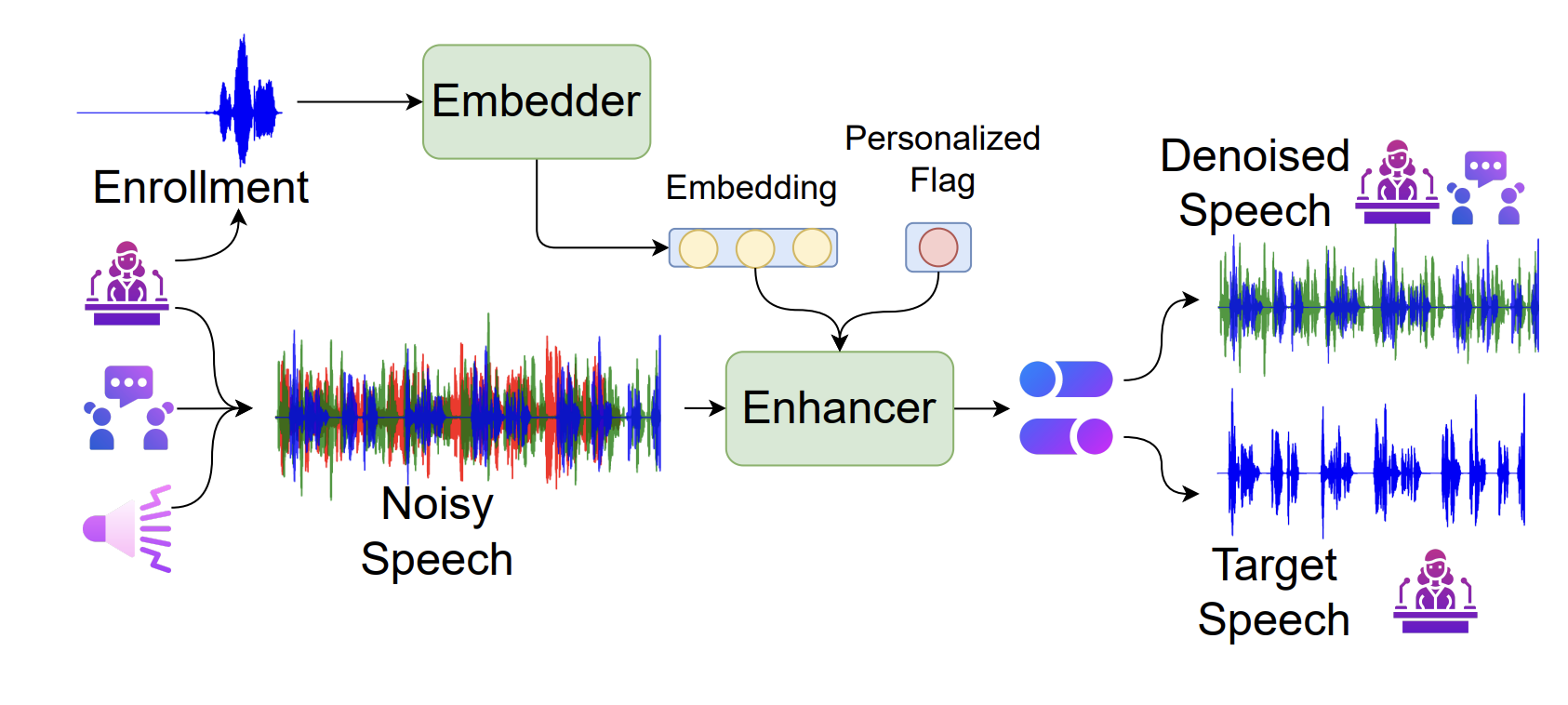
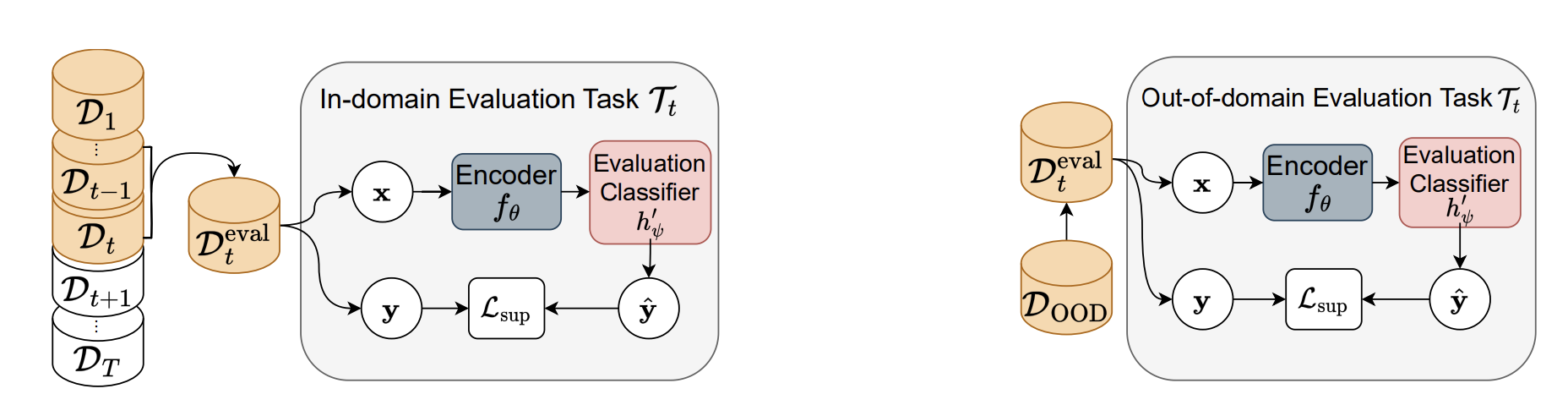
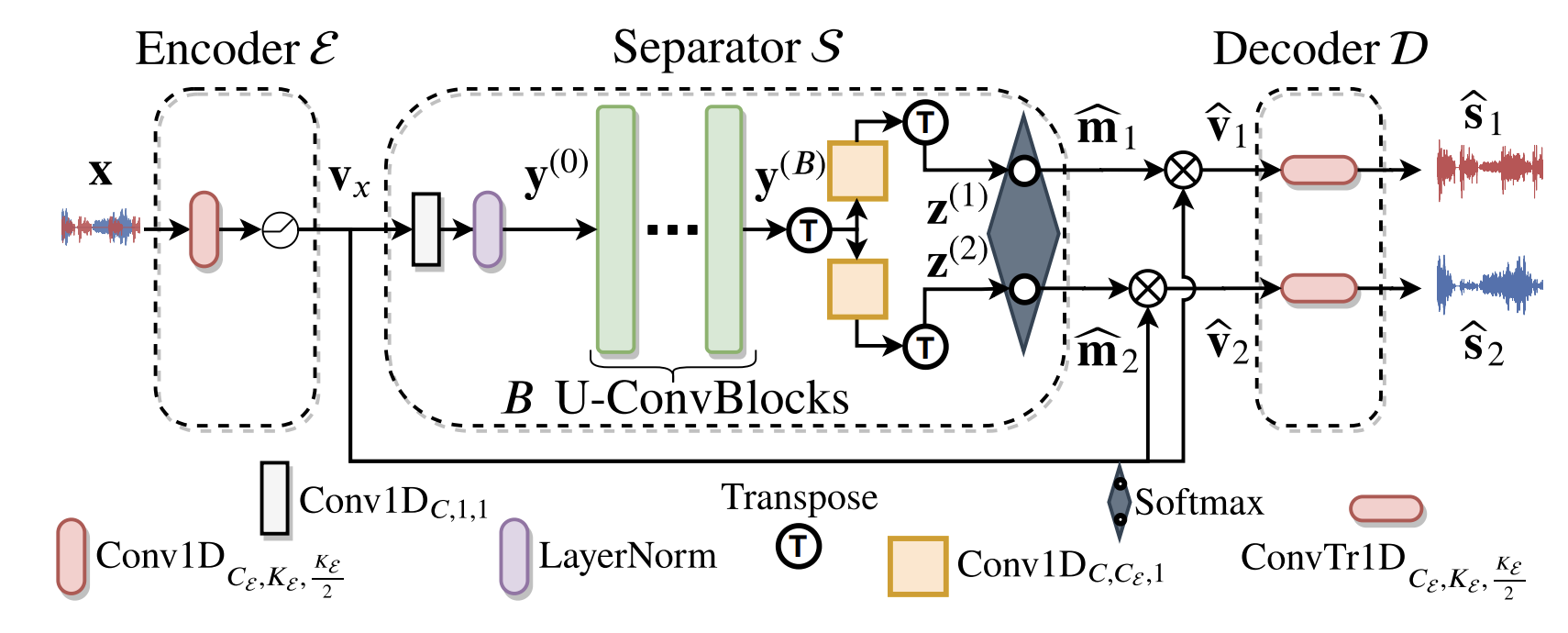
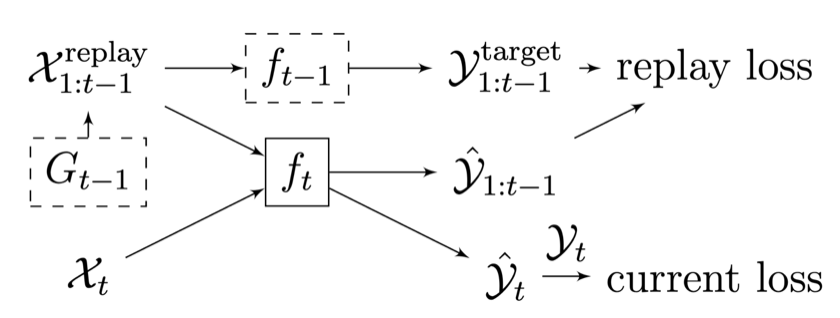
Continual Learning of New Sound Classes Using Generative Replay
Updates
May 2024
I have joined Adobe as a Research Scientist/Engineer under MusicAI Group.
Sep 2023
I have started my role as an applied scientist at AWS ChimeSDK Audio Science team.
Aug 2023
I have succesfully defended my thesis, “Data-Efficient Approaches for Audio Classification and Separation”. Slides are also available.
Citation